Multimodal AI with LLaVA on Databricks
LLaVA, among other multimodal AI models, leaps from standalone large language models and allows us to engage with AI in novel ways.


Table of Contents
Artificial intelligence (AI) sparks our curiosities and engages our imaginations - so much so that we wonder what life may be like in the near and distant future. At least for me AI has this effect. Will cars fly? Will we have chips in our brains? And will we invent artificial general intelligence (AGI). With every advancement in the field of AI, AGI feels paradoxically closer but yet so far. One thing is for certain - to continue to close the gap - our AI systems must sense and process multiple external stimuli simultaneously including in different modalities.
This post focuses on leveraging recent generative AI advancements particularly with multimodal AI models. Multimodal AI models often combine two models that excel in a singular modality. We will focus on one example of a multimodal model - LLaVA. We’ll study how the model is designed, how the model works, and how we can leverage the Databricks platform to play around with the model. First let’s discuss the LLaVA model itself.
If you are curious about general topics in the AI space, check out these other recent posts focusing on AI: Object Detection with YOLOv8 on Databricks, Getting Started with OpenAI, Hands-on with Edge AI, and Getting Started with Databricks, the Data + AI company.
About LLaVA
LLaVA has exploded in popularity with over 3 million downloads in the last month on HuggingFace (counting all of the variants, more on this topic later). This hype is warranted as the model family introduces multimodal capabilities similar to OpenAI’s GPT-4.
LLaVA is an acronym for “Large Language and Vision Assistant” and, as we’ve learned, introduces multimodal capabilities for generative AI. But what does this mean? In this case, LLaVA combines two models to perform tasks - a vision encoder to interpret visual/image data and a large language model (LLM) to facilitate text parsing and understanding. Conceptually, you can think of LLaVA as more of a framework or architecture as opposed to an individual model. In fact, there are dozens of variants that substitute different underlying models with different parameter sizes (e.g., 7b, 13b, 34b).

LLaVA network architecture showing language model and vision encoder.
Of course, this generalization of the network architecture underestimates the underlying complexity but that is outside of the scope of this post. If you’re curious, read more at arXiv and Haotian Liu’s Github repo.
The LLaVA website provides a webapp to let us interact with a model. Let’s look at this screenshot to see how an image and a text prompt are supplied to the model. The model responds as if you had just nudged your friend and said, “hey what’s going on over there?”
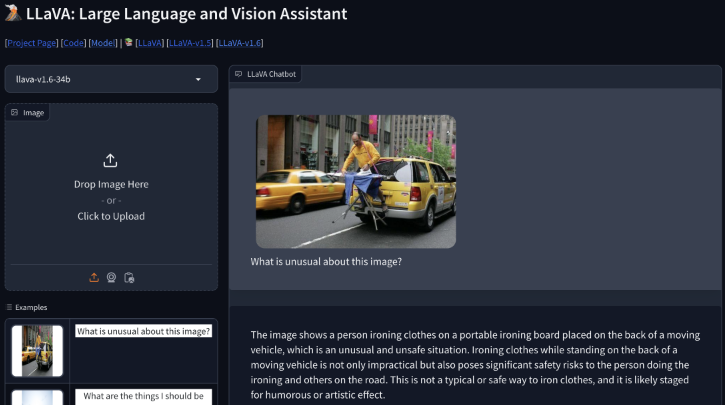
We pass an image and a prompt and receive a response from LLaVA demonstrating understanding of the complexities within the image. (Source: https://llava-vl.github.io/)
The model interprets the scene and actions within an image and understands the prompt. This is an exciting opportunity to demonstrate mixed modality learning. But for now, we have enough information to get started. Now that you understand what LLaVA offers, we will take a look at why Databricks will play a role as the platform and compute provider for this exercise.
About Databricks
![]() As discussed in the previous post, Databricks is the creator of the Lakehouse architecture/concept, now adopted by 74% of enterprises according to MIT Review, and technologies included in the modern data architecture including Spark, Delta Lake, and MLFlow.
As discussed in the previous post, Databricks is the creator of the Lakehouse architecture/concept, now adopted by 74% of enterprises according to MIT Review, and technologies included in the modern data architecture including Spark, Delta Lake, and MLFlow.
Using Databricks we can easily build data pipelines to handle structured, semi-structured, and unstructured datasets - including images. While data pipelines and large data volumes are not the focus of this post, the capability to scale this solution is an important consideration for production-ready data deployments. Additionally, using Databricks, we can seamlessly transition our projects between data engineering focus and machine learning focus - a feature that would be beneficial if we had to handle newly arriving data. Databricks has a long list of features for data engineering, data analytics, data science, machine learning, and artificial intelligence projects but the handful that we will use extensively in the LLaVA example include:
- GPU-enabled clusters (including easily imported external libraries like
transformersandtorch) - MLflow for model tracking, evaluation, and serving
- Unity Catalog for unified data and AI governance (ensuring permissions/access management on our AI model)
- Databricks Volumes (for storing binary/non-tabular data like model checkpoints)
Multimodal AI with LLaVA on Databricks
Overview
For this exercise, we will be exploring 1) the LLaVA model and its capabilities as well as 2) the Databricks platform and its capabilities for registering and serving models. In our previous post, we looked at tuning the YOLOv8 model on a relatively small tuning data set. In this post, we will not emphasize the training or tuning elements instead choosing to look at the experiment tracking, model registration, and model serving steps for using an AI model. For these steps we will use MLflow.
More specifically, we will accomplish this AI model exercise by completing the following steps:
- Retrieve the LLaVA model from HuggingFace, caching the ~15 GB in Databricks Volumes to avoid constantly redownloading in each session
- Use MLflow to create a model signature, log a
mlflow.pyfuncmodel, and register the model in Databricks Unity Catalog model registry - Use Databricks to create a model endpoint for real-time or batch AI inferencing
Let’s dive in!
Setup
Authenticate to HuggingFace
Note: This step is not required if you have already retrieved the model checkpoints and have them cached.
1from huggingface_hub import notebook_login
2
3# Login to Huggingface to get access to the model
4notebook_login()You will receive a prompt requesting an access token from HuggingFace.
HuggingFace prompt to login via token within a Databricks notebook.
Configure environment
For reproducibility and general stability, we configure our environment with consistent package versions. At the time of this post, the versions for critical packages are: transformers==4.39.0, mlflow==2.11.3, tensorflow==2.16.1.
1%pip install --upgrade transformers==4.39.0 mlflow>=2.11.3 tensorflow==2.16.1We restart python to make any version changes visible throughout the environment.
1dbutils.library.restartPython()Set cache location
Since we’re dealing with a large model, we want to avoid unnecessary downloads and ensure relatively quick access to the model checkpoints in the case we need to load or reload the model into GPU memory. Make sure you set the environment variable correctly. In our case, we’ll point the cache to look at our location in Databricks Volumes.
1import os
2os.environ["HF_HOME"] = "/Volumes/benhayes/test/test_llava"MLflow & Model Management
We’re now in the 2nd section where we will focus on the model and the usage of mlflow and transformers.
Model name and signature
We need to create a model signature which in future releases of MLflow will be required. Fortunately, mlflow.models simplifies this process by allowing us to infer the signature from a schema or from sample model input and output. Let’s do the latter. We submit two strings as input - one is a URL to an image and the other is a prompt. We receive one string as output. Note that our sample includes two examples contained in arrays.
1model_id = "llava-hf/llava-v1.6-mistral-7b-hf" 1import numpy as np
2from mlflow.models import infer_signature
3
4signature = infer_signature(
5 model_input=np.array(
6 [
7 ["<Some URL 1>", "<Some instruction 1>"],
8 ["<Some URL 2>", "<Some instruction 2>"],
9 ]
10 ),
11 model_output=np.array(
12 [
13 ["<Sample output 1>"],
14 ["<Sample output 2>"]
15 ]
16 ),
17)Model logging
Our next task is a bit more complicated. We begin to work with the transformers library which will streamline our usage of the LLaVA model. Additionally, mlflow will be used to log the model for tracking purposes. Here's a few important notes about this step:
- Within the
.from_pretrained()call we specify acache_dirto load the model from cache. If we haven’t configured this properly, we will trigger a download of the model (~15 GB!) - We define a class called
Modelwhich inherits frommlflow.pyfunc.PythonModel - Our class’
.predict()method takes input and procedurally processes results. This could be optimized further - We call
mlflow.start_run()andmlflow.pyfunc.log_model()to log the model and we specify certainpip_requirements=[…]to ensure dependencies are not lost in this process
1import mlflow
2import pandas as pd
3
4from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
5import torch
6from PIL import Image
7import requests
8
9
10class Model(mlflow.pyfunc.PythonModel):
11 def __init__(self):
12 self.processor = LlavaNextProcessor.from_pretrained(model_id)
13
14 self.model = LlavaNextForConditionalGeneration.from_pretrained(
15 model_id,
16 torch_dtype=torch.float16,
17 low_cpu_mem_usage=True,
18 cache_dir="/Volumes/benhayes/test/test_llava")
19
20 self.model.to("cuda:0")
21
22 def predict(self, context, model_input):
23 processor = self.processor
24 model = self.model
25
26 results = []
27
28 for mi in model_input:
29
30 img_url = mi[0]
31 prompt = mi[1]
32 image = Image.open(requests.get(img_url, stream=True).raw)
33
34 # Prepare inputs
35 inputs = processor(prompt, image, return_tensors='pt').to(0, torch.float16)
36
37 # Generate and store response
38 output = model.generate(**inputs, max_new_tokens=150, do_sample=False)
39 result = (processor.decode(output[0], skip_special_tokens=True))
40
41 results.append(result)
42
43 return results
44
45
46# Save the function as a model
47with mlflow.start_run():
48 mlflow.pyfunc.log_model(
49 "model",
50 python_model=Model(),
51 pip_requirements=['transformers==4.39.0', 'mlflow==2.11.3', 'tensorflow', 'torch', 'Image', 'requests'],
52 signature=signature
53 )
54 run_id = mlflow.active_run().info.run_idWithin the Databricks notebook, we’ll see output below the executed cell cluing us into the status. Note that we loaded the model from our Databricks Volumes cache where the output says “Loading checkpoint shards: … 0/4”.
preprocessor_config.json: 0%| | 0.00/754 [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/1.85k [00:00<?, ?B/s]
tokenizer.model: 0%| | 0.00/493k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/1.80M [00:00<?, ?B/s]
added_tokens.json: 0%| | 0.00/41.0 [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/552 [00:00<?, ?B/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 0%| | 0/4 [00:00<?, ?it/s]
Uploading artifacts: 0%| | 0/9 [00:00<?, ?it/s]
Uploading /local_disk0/repl_tmp_data/ReplId-4a7ca-90fe8-f0db9-6/tmp347uxv9_/model/python_model.pkl: 0%| …At this point the LLaVA model has been fetched from HuggingFace, cached in Databricks Volumes, logged to MLflow with dependencies and we’re ready to move onto endpoint configuration and inferencing!
Endpoint & Inferencing
At this point we could inference the model - but remember - our goal isn’t just to inference but to set up reusable infrastructure for inferencing now and in the future, for updating our model as weights change, and for monitoring results for drift, etc.
With that in mind, we want to set up a model serving endpoint (“endpoint” for short). We can do this with relative ease using Databricks Model Serving.
Register model
First we will register the model. We’ll use the Databricks Unity Catalog model registry so that we can later seamlessly apply permissions to this model. We need to specify a catalog name, schema name, and model name. We also specify that we wish to use the Databricks UC registry by passing in “databricks-uc” to mlflow.set_registry_uri(). When we register the model, we receive a model object which we’ll use to find the version number later.
1import mlflow
2catalog_name = "benhayes"
3schema_name = "test"
4model_name = "llava_1-6"
5mlflow.set_registry_uri("databricks-uc")
6model_version_obj = mlflow.register_model(
7 model_uri=f"runs:/{run_id}/model",
8 name=f"{catalog_name}.{schema_name}.{model_name}"
9)Here, the results of the registration process are displayed - note that we are on version 5 because I have previously executed these cells 4 times:
Registered model 'benhayes.test.llava_1-6' already exists. Creating a new version of this model...
Downloading artifacts: 0%| | 0/9 [00:00<?, ?it/s]
Downloading /local_disk0/repl_tmp_data/ReplId-4a7ca-90fe8-f0db9-6/tmpcybvrlkf/model/python_model.pkl: 0%| …
Uploading artifacts: 0%| | 0/9 [00:00<?, ?it/s]
Uploading /local_disk0/repl_tmp_data/ReplId-4a7ca-90fe8-f0db9-6/tmpcybvrlkf/model/python_model.pkl: 0%| …
Created version '5' of model 'benhayes.test.llava_1-6'.Second, we want to give the model an alias so we can refer to the correct version when inferencing. This alias is also helpful for other reasons regarding programmatic access and monitoring. We instantiate an MlflowClient() and specify the model we want using the catalog.schema.model notation. We also need to provide the model version we want to have the alias applied to so that we use the model and retrieve the version attribute.
1from mlflow import MlflowClient
2client = MlflowClient()
3
4model_alias = "jollibee"
5
6# create alias for the model version
7client.set_registered_model_alias(f"{catalog_name}.{schema_name}.{model_name}", model_alias, model_version_obj.version)Create Model Endpoint
Next, we need to create an endpoint to serve the model currently registered in MLflow. We pass in model details to create_endpoint() and provide a config including workload_type as GPU_MEDIUM. This config ensures the cluster powering the model endpoint has GPU capabilities (A10).
1from mlflow.deployments import get_deploy_client
2
3client = get_deploy_client("databricks")
4endpoint = client.create_endpoint(
5 name="llava-model-endpoint",
6 config={
7 "served_entities": [
8 {
9 "name": "llava-model-endpoint"
10 "entity_name": f"{catalog_name}.{schema_name}.{model_name}",
11 "entity_version": f"{model_version_obj.version}",
12 "workload_type": "GPU_MEDIUM",
13 "workload_size": "Small",
14 "scale_to_zero_enabled": false
15 }
16 ]
17 }
18)This process can take a few minutes, and for models that require GPUs and heavy libraries like tensorflow and/or torch, this process could take up to an hour to deploy the model endpoint. Using Databricks, there will be logs available in the UI and also via API to check on the status of the model endpoint deployment.
Once our model is ready, we are all set for inferencing! We can do this with simple REST calls to the model endpoint. I’ve obscured the URL for security reasons but this endpoint will receive REST calls and return a response with the results. We could build this into a Streamlit, Gradio or another app so that end users can take advantage of the multimodal model!
There exist many use cases where having text prompt and image input are useful. Just to pick one for fun, let’s see if we can get our model to extract information from a sample paystub. This could be helpful for automating document-heavy workloads and improving OCR performance.
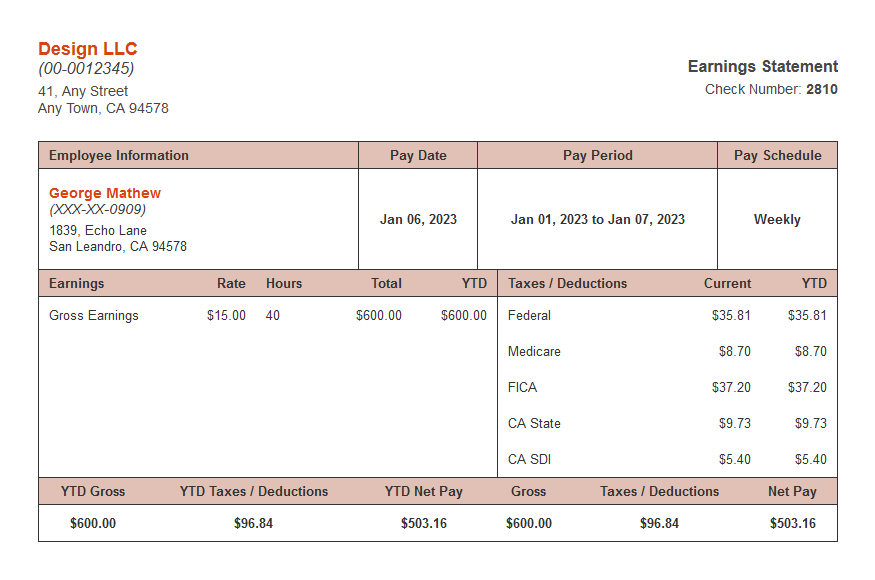
Sample pay stub image that we will use to perform OCR with LLaVA. (Source: https://www.securepaystubs.com/)
1import requests
2import json
3
4img_url = "https://www.securepaystubs.com/assets/images/templates/classic/meadow-paystub.png"
5prompt = '[INST] <image>\nPlease extract the employee name, employee address, and check number in the following JSON format: {"emp_name": <Employee Name>, "emp_address": <Employee Address>, "check_no": <Check Number>}. Please fill in the fields delimited by <>[/INST]'
6
7data = {
8 "inputs": [(img_url, prompt)]
9}
10
11API_TOKEN = "||REDACTED||"
12headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
13
14response = requests.post(
15 url="https://.../serving-endpoints/llava-model-endpoint/invocations", json=data, headers=headers
16)
17
18print(json.dumps(response.json()))After constructing an HTTP request and specifying our paystub image and prompt as part of the payload, we receive a response. Here is the response from the LLaVA model served by Databricks Model Serving. Note that the output has been cleaned up slightly (removed escape characters, etc.).
{"emp_name": "George Matthew", "emp_address": "1839 Echo Lane, San Leandro, CA 94578", "check_no": "2810"}Wow! The LLaVA model which had no additional training or tuning performed by us was able to extract a name, address, and check number from a mock paystub. Notice that the model even returned valid JSON. With close monitoring, of course, we could use this model to perform this task or many more!
Witnessing the generative AI boom, which continues to show momentum, is astonishing even for someone who has been in tech for more than a decade. The recent wave of multimodal AI advancements generates optimism that the AI renaissance continues. Without doubt, developing models that support multiple modalities - without sacrifice in either modality - advances the data and AI field toward artificial general intelligence (AGI).
Let’s recap what we covered in this post - we did a lot. We learned about multimodal AI, the LLaVA model architecture, Databricks and the Data Intelligence Platform, and deployed LLaVA via Databricks and MLflow. Our LLaVA model, deployed via Databricks Model Serving endpoint, given a text and image prompt, returned results with accuracy and speed. We extracted text with relative ease from a previously unseen image. The beauty of this process is the models have been abstracted, so as advancements continue, the model can be swapped in, cached, registered, etc. Or if the use case changes, the prompt and model signature can change/adapt.
Stay tuned for more posts about AI, data science, and tech!
Note: Please reach out if you are interested in seeing the notebook with the full code.
