Getting Started with Databricks
Databricks is the Data + AI company and the provider of a leading data science and machine learning platform.


Table of Contents
Recently, I completed two certifications with Databricks: Certified Associate Developer for Apache Spark 3.0 and Certified Professional Data Scientist. Both require a two hour proctored certification exam. For more information visit the Databricks certifications page.


A natural question to ask is why? Well, Databricks is a rapidly growing company that offers a powerful yet easy to learn or use platform for data engineering and data science. The platform provides a notebook-like interface to interact with your organizaton’s data whether large or small. You can use any of the 3 major cloud providers (e.g., Amazon AWS, Microsoft Azure, Google Cloud) which makes integration into an existing cloud environment easier. Continue reading to learn how to get started with Databricks!
Apache Spark
Apache Spark is an open source analytics and compute engine that supports parallelism and fault tolerance. Spark’s initial release in 2014 accelerated the adoption of big data and has since been improved with the addition of dataframes, machine learning capabilities, and streaming. Databricks leverages Apache Spark through it’s notebook based platform. For more information check out these Wikipedia articles: Apache Spark and Databricks and ensure you at least have a high-level understanding of the Spark architecture shown below.
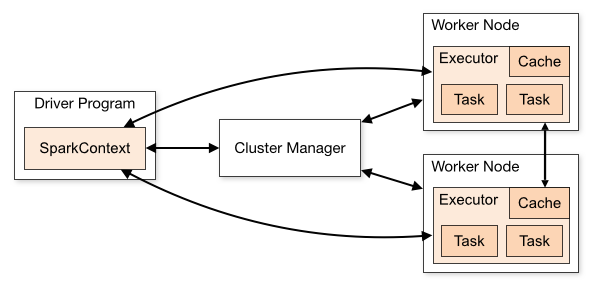
Jobs can be processed in parallel using multiple worker nodes.
Source: https://spark.apache.org/docs/latest/cluster-overview.html
Tools and Language Support
Assuming you have familiarity with data engineering (i.e., using tools like spark or pyspark) or data science (i.e., applying machine learning, using sklearn), learning how to use Databricks and the associated tools for your next project is easier. It’s also helpful to learn about the history of the company and how the company was founded by the creators of Apache Spark, MLflow, and Delta Lake. These tools are popular outside of Databricks but have formed the foundation for Databrick’s comprehensive, collaborative, and cloud-based platform.
The Databricks Lakehouse platform is built around the following tools, in addition to others:
- Delta Lake
- Spark
- MLflow
- Koalas (in Spark 3.2, workloads using pandas can be scaled using the pandas API on PySpark)
Databricks supports these languages - as long as you know one you should be okay, though it would be helpful to know two or more.
- Python
- R
- SQL
- Java
- Scala
Workload Types
You can customize the Databricks experience by selecting from a set of workload types. There are four options listed on the Databricks pricing page. The three original workload types (all but SQL compute) are described in detail in the Databricks administrator guide. For more information look at the differences highlighted on the pricing page.
- Jobs Light compute
- Jobs compute
- SQL compute
- All-purpose compute
Once you have familiarity with spark it’s time to navigate to databricks.com and create an account. For this post, we will be using a community account which is restricted to a subset of features but great for acclimating to the platform. As of now all you need is a name, company, email address, and title. For frequently asked questions check out this FAQ page.

Signing up to try Databricks takes only a few clicks
Once your account is created, you’ll be able to log in to view the Databricks Community Edition. The homepage has convenient links to view a tutorial, import data, other common tasks, recent notebooks, and news that may be relevant to you. By opening the left-hand panel you’ll find the ability to create notebooks, tables, and clusters. Additionally, there you can view databases, tables, clusters, and jobs. This panel would contain additional options if you were to advance from the community edition.
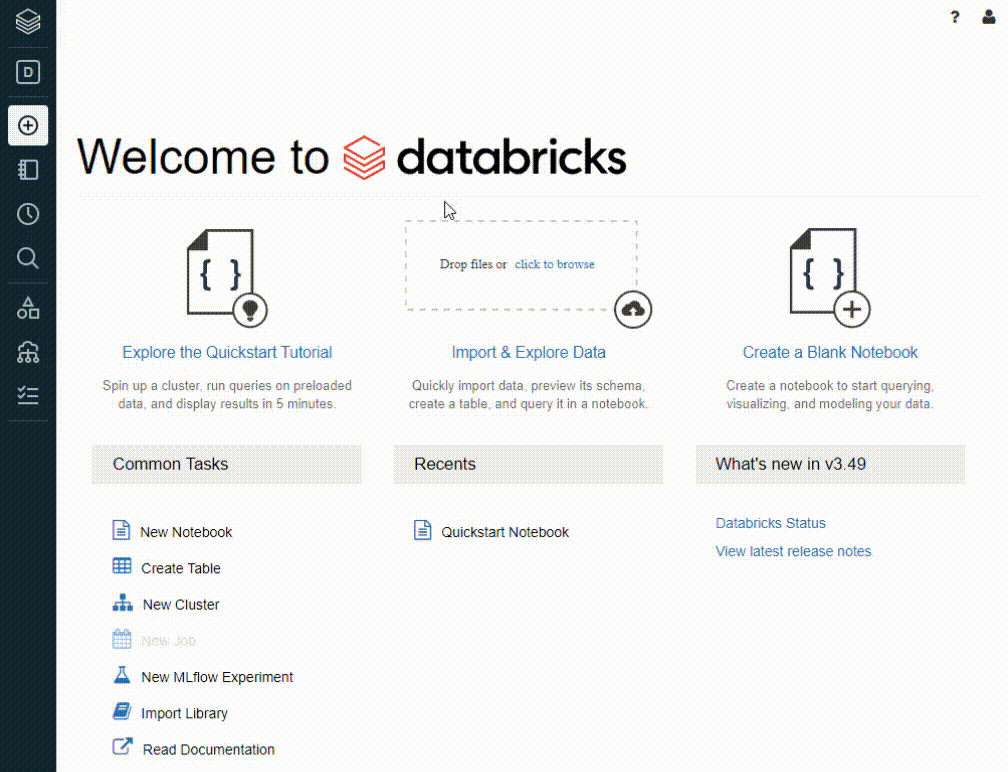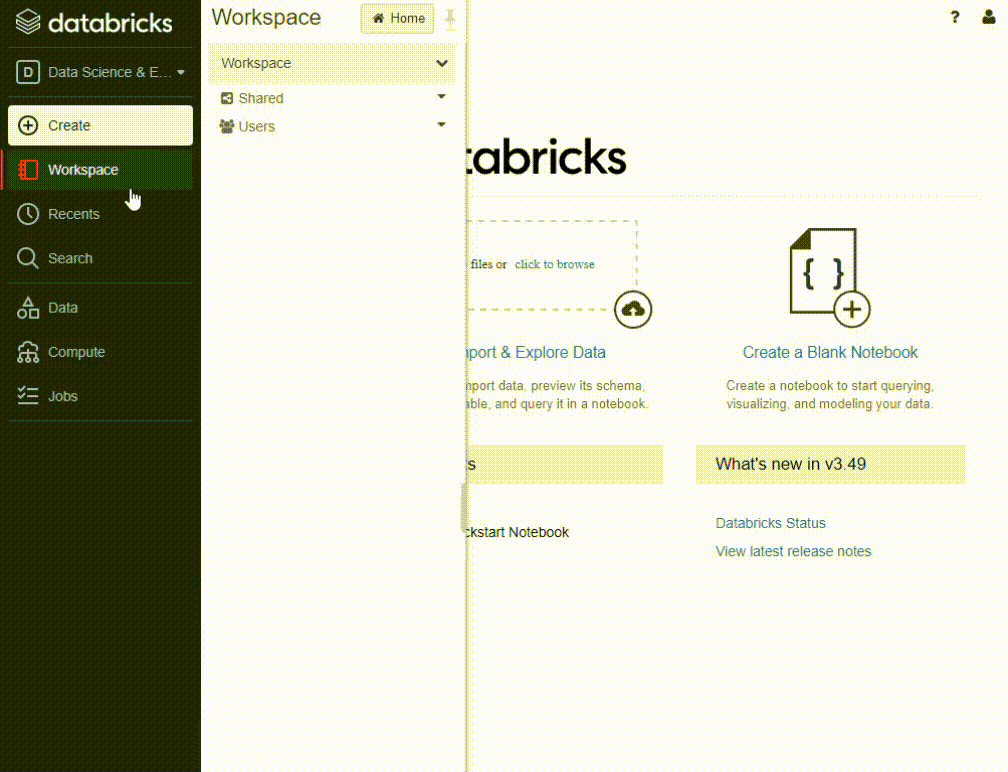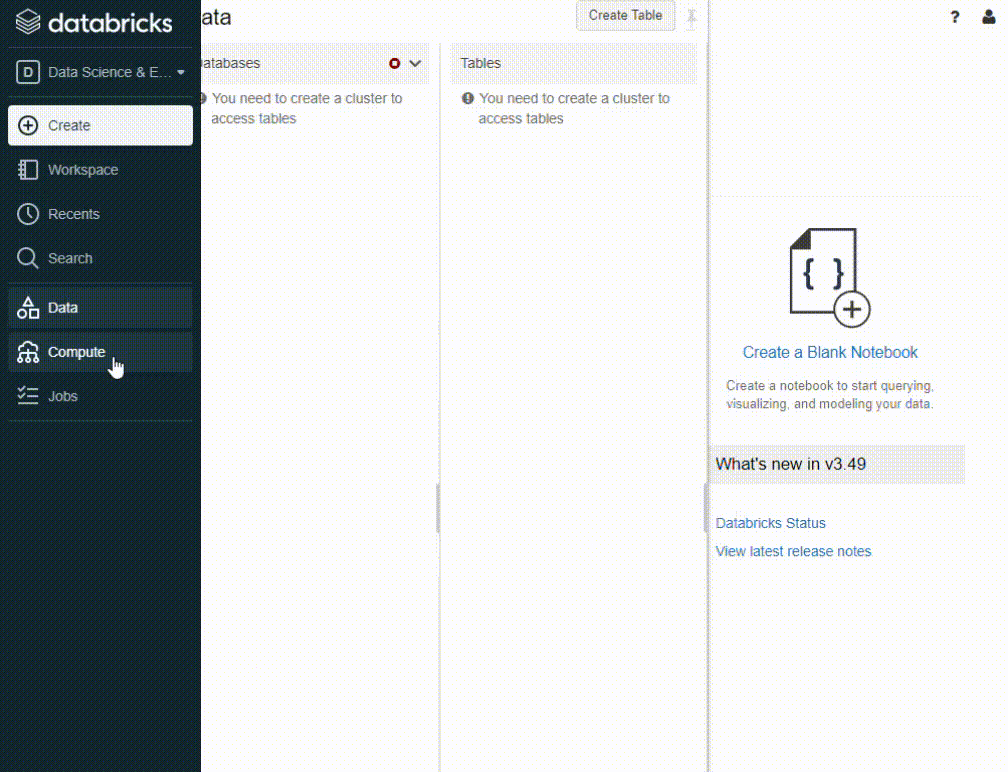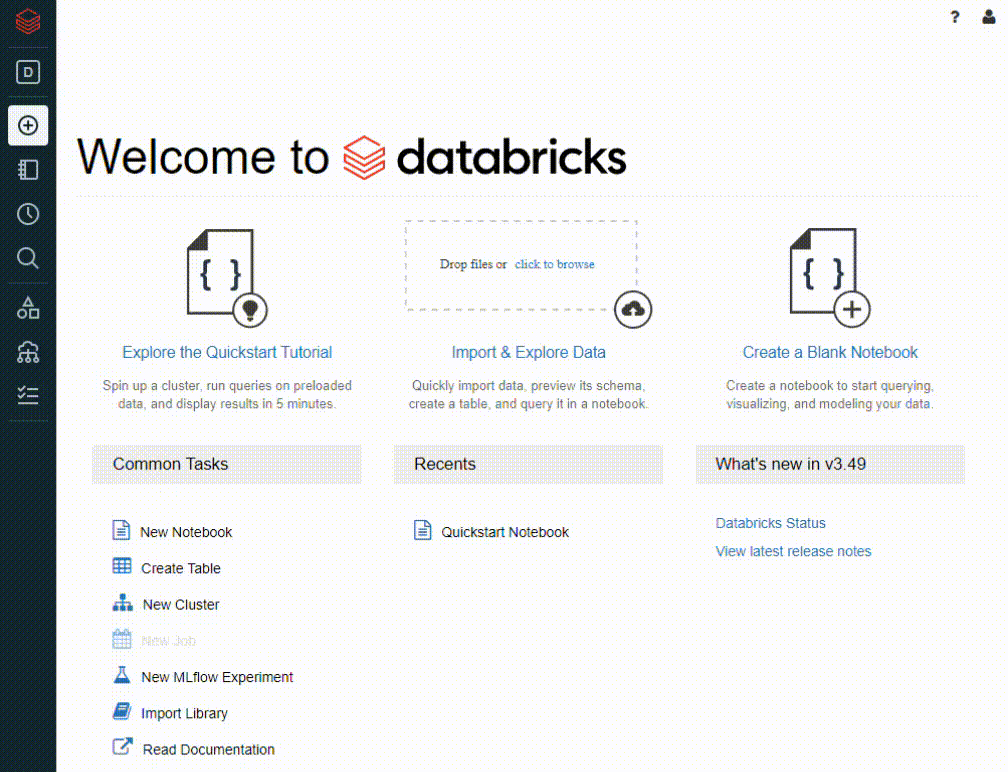
Community Edition ofters a foundation of great features to manage data easily
Cluster Settings
Setting up a cluster is an important step and can impact your experience while using Databricks. Pay attention to the Databricks Runtime Version as the options here are important if you intend to perform machine learning or otherwise have a heavy workload. If this is the case, you may wish to opt for an ‘ML’ runtime version. From this page, you can also adjust the instance geography or configure Spark and environment variables.
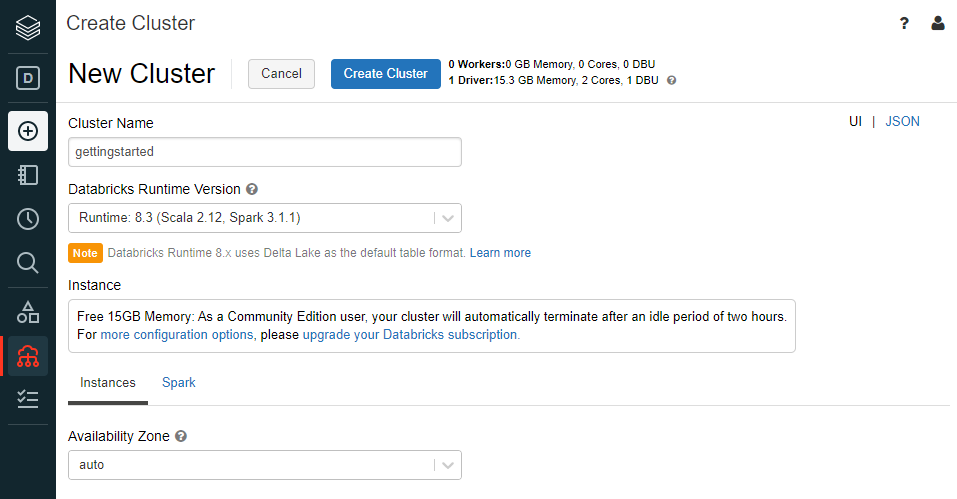
Setting up a cluster in Databricks Community Edition
You’ll notice some of the limitations of the community edition here as there are only 15GB of memory, idle time limits, and 0 worker nodes. For a brief explanation of Spark architecture and why workers are advantageous, checkout this link which explains how Spark can run on a cluster. For now, the default settings will be good enough for us to get started.
Importing Data and Notebooks
Let’s assume you already have a dataset and have started analysis on a notebook. You’ll find that it is simple to import your data into the data lake and notebooks into the cluster environment. As a data scientist by training and experience, I would most likely upload a jupyter notebook (e.g., .ipynb file) but you can also upload other common formats such as .py, .sql, .Rmd. You may also find .dbc files useful if you are sharing multiple files of different types.
For the sake of example, let’s load in one of my previous Jupyter notebooks - the results of which you can find in this post (Analyzing Suspicious IP Addresses). Notice how the code and markdown cells are recognized and preserved, though for obvious reasons, relative references (e.g., images) will not be automatically imported.
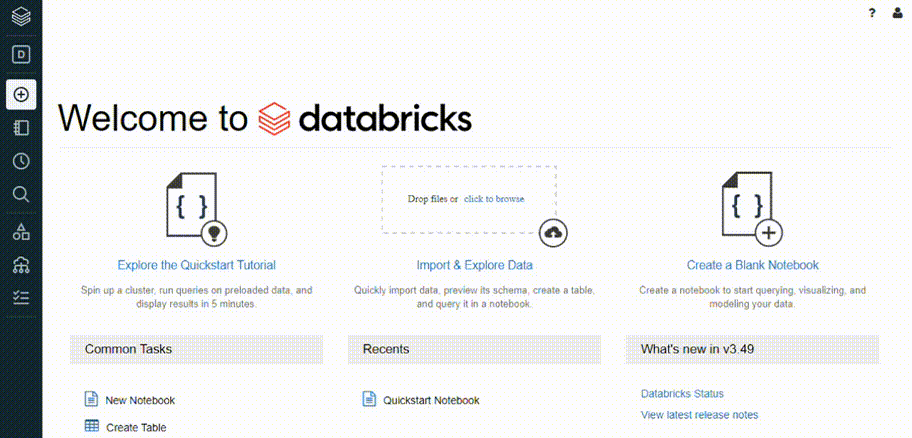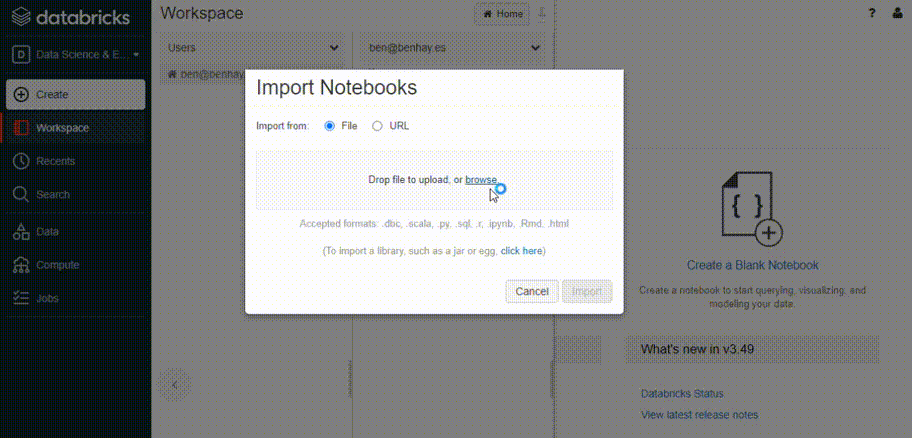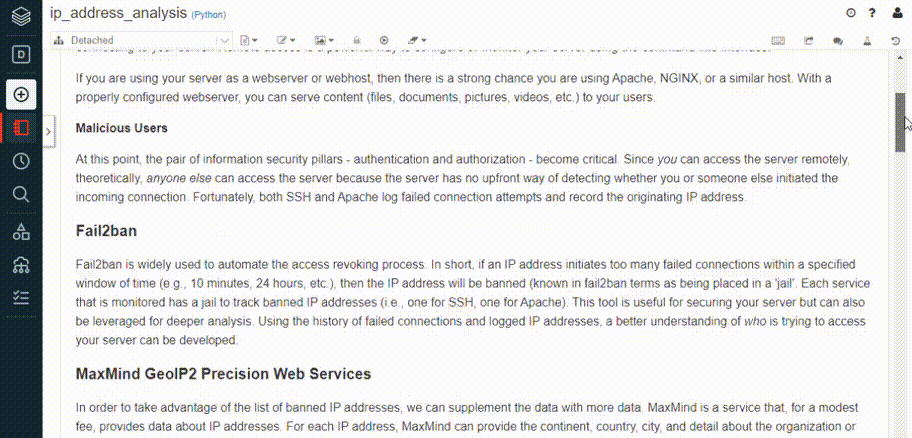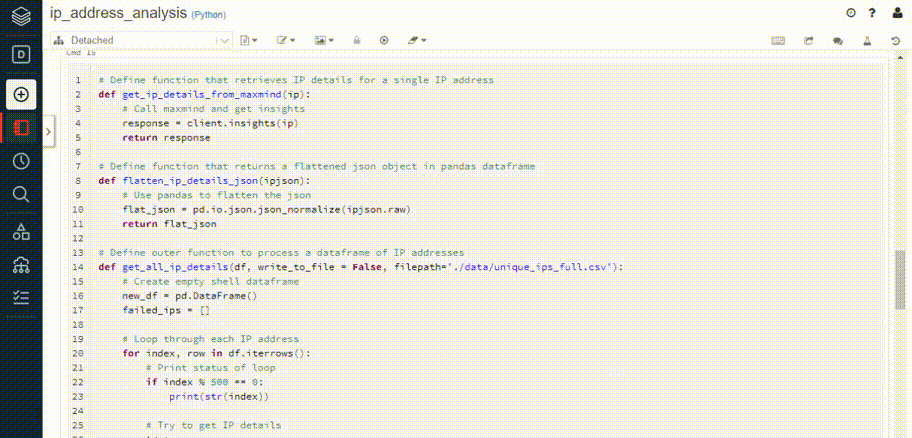
Importing an existing Jupyter notebook can accelerate existing projects
Advancing from the Community Edition
You have seen the features of the Databricks Community Edition but there are many more features available. For a full description of the differences, take a look at the Databricks documentation. There is a long list of features that are worth exploring in the Databricks platform:
- MLflow
- Koalas (or using the pandas API on Spark)
- Delta Lake
- Time Travel
- FeatureStore
- Streaming
We have covered a small sample of the features available in Databricks. Use the additional resources below to continue learning about how Databricks can help your use case - including exciting new features like Feature Store. As you can see, Databricks and the Databricks Lakehouse platform accelerates analysis, collaboration, and communication - shortening the distance between database managers, data engineers, data scientists, and decision makers.
Here are some additional resources to continue diving into Databricks and learn how the platform can accelerate your data projects. The Path Training is particularly useful if you are getting started with a particular role in mind. Also, Databricks provides updates on new features using its Youtube channel.
Additional Resources
- Databricks - Help (Knowledge Base, Documentation, Training)
- Databricks - Path training
- YouTube: Databricks - Delta Lake on Databricks Demo (8:58)
- YouTube: Databricks - Data Science and Machine Learning on Databricks Demo (10:55)
- YouTube: Databricks - Making Apache Spark better with Delta Lake (58:09)
- YouTube: Databricks - Lakehouse with Delta Lake Deep Dive (2:41:51)
- YouTube: Databricks - Announcing Databricks Machine Learning, Feature Store, and AutoML | Keynote Data + AI Summit NA 2021 (38:29)
- Databricks - MLflow Guide
- Apache - Spark
- Udemy - Databricks
