Optimizing Language Models with DSPy
Prompt engineering language models lacks necessary refinement especially for enterprise solutions. Optimize your language models with DSPy!


Table of Contents
Feeling let down by prompt-engineering? Tired of fickle prompts that worked yesterday but not today? Need to swap in a newer, more powerful model but afraid your prompts won’t transfer reliably? You aren’t alone - a common point of feedback from AI researchers, developers, and enterprise decision-makers is that generative AI solutions lack robustness and enterprise reliability - so far.
Whether you are building a retrieval augmented generation (RAG) or a more complex solution, building around generative AI models requires tedious efforts from teams to ensure the outputs align with the needs of the users and business. Additionally, as single-model AI solutions give way to compound AI systems, having the right tooling can mean the difference between success and failure, between reliability and fragility.
What is DSPy?
In October 2023, researchers at Stanford University introduced DSPy - a framework that provides developers and researchers with the ability to systematize usage of language models. In other words, users can algorithmically control how language models interact with other parts of an AI system. Instead of relying on manual prompting in isolation for a given step of a process/chain, users leveraging DSPy can define modules and optimizers - more on these concepts later.
This is a new paradigm in which LMs and their prompts fade into the background as optimizable pieces of a larger system that can learn from data. tldr; less prompting, higher scores, and a more systematic approach to solving hard tasks with LMs.
Let’s build up our intuition of what DSPy does so we can understand how it works so well. First, let’s breakdown what DSPy components are available today.
What are the components of DSPy?
As mentioned above, DSPy is a framework or another tool in your AI-toolkit that enables you to build robust, compound AI systems. In this section we'll cover the following components of DSPy and how to approach using them for your own projects:
Signatures
Signatures express what we expect the language model to do without relying on meticulously detailing how it should be completed. By using signatures, our code will be more modular and has built-in support reproducibility.
Code:
1sentence = "You are a nice person."
2
3classify = dspy.Predict('sentence -> sentiment')
4classify(sentence=sentence).sentimentOutput:
'Positive'Modules
As we aim to modularize our AI system code, we have access to modules in DSPy.
Modules act as layers in a pipeline that give us access to signature based language model interactions. In the example below, we use the most basic module dspy.predict() but others include: dspy.ChainOfThought(), dspy.ProgramOfThought(), dspy.ReAct(), dspy.MultiChainComparison().
Code:
1sentence = "You are a nice person."
2
3# 1) Declare with a signature.
4classify = dspy.Predict('sentence -> sentiment')
5
6# 2) Call with input argument(s).
7response = classify(sentence=sentence)
8
9# 3) Access the output.
10print(response.sentiment)Output:
'Positive'Data
While using DSPy, we need to define what data we are using. By defining inputs, intermediate labels (optional), and final labels (optional), we can programmatically interact with different examples.
DSPy relies on the Example object which contain key-value pairs. Additionally, examples can be marked as inputs using example.with_inputs().
Code:
1qa_pair = dspy.Example(question="This is a question?", answer="This is an answer.")
2
3print(qa_pair)
4print(qa_pair.question)
5print(qa_pair.answer)Output:
Example({'question': 'This is a question?', 'answer': 'This is an answer.'}) (input_keys=None)
This is a question?
This is an answer.Metrics
We move on to metrics so we begin to think with the outcome in mind - what are we looking to achieve, what is important to us? Metrics in DSPy allow us to define functions that will score the results of a model task. These are powerful because they are flexible, programmatic, and traceable (outside of the scope but you can learn more here).
In the example below, we define a metric as a function and evaluate both the answer as well as the context - giving us a multi-perspective view into quality and, over time, consistency.
1def validate_context_and_answer(example, pred, trace=None):
2 # check the gold label and the predicted answer are the same
3 answer_match = example.answer.lower() == pred.answer.lower()
4
5 # check the predicted answer comes from one of the retrieved contexts
6 context_match = any((pred.answer.lower() in c) for c in pred.context)
7
8 if trace is None: # if we're doing evaluation or optimization
9 return (answer_match + context_match) / 2.0
10 else: # if we're doing bootstrapping, i.e. self-generating good demonstrations of each step
11 return answer_match and context_matchOptimizers
Within DSPy an Optimizer is an algorithm that optimizes the prompts and language model weights. This tuning is performed with respect to the metrics that we defined. According to the DSPy docs (Optimizers), an Optimizer requires 3 inputs: a DSPy program (one or more modules), a metric, and a few training inputs.
1from dspy.teleprompt import BootstrapFewShotWithRandomSearch
2
3# Set up the optimizer: we want to "bootstrap" (i.e., self-generate) 8-shot examples of your program's steps.
4# The optimizer will repeat this 10 times (plus some initial attempts) before selecting its best attempt on the devset.
5config = dict(max_bootstrapped_demos=4, max_labeled_demos=4, num_candidate_programs=10, num_threads=4)
6
7optimizer = BootstrapFewShotWithRandomSearch(metric=YOUR_METRIC_HERE, **config)
8optimized_program = optimizer.compile(YOUR_PROGRAM_HERE, trainset=YOUR_TRAINSET_HERE)Now that we have examined each of these components within DSPy individually, we can get a high-level overview of all of them. Refer to the table below for a summary of each component.
| Component | Description |
|---|---|
| Signature | Expected behavior of a module including input and output. |
| Module | Conceptual and functional building block of a DSPy program (a program that uses language models). Can be chained together to form multi-module programs. Required as an input to an Optimizer. |
| Data | Training inputs often supplied to Optimizer. Defined in a similar fashion to python dictionaries but with extra utilities. |
| Metrics | A function defined to evaluate the quality or performance of a task by a language model. |
| Optimizers | A component to tune the prompts or weights used in language model tasks. Composed of modules, metrics, and training inputs. |
Now that we understand how each component is used, let’s walk through an example of how to use DSPy. In the next section, we’ll explore an end-to-end example of using DSPy to optimize a large language model.
In this section, we will build a multi-hop program that extends a retrieval augmented generation (RAG) approach. Often times, RAG solutions are insufficient for real-world use cases. User queries are more complex or require chain of thought or reasoning to provide an answer.
Installation
Fortunately, installing DSPy is incredibly simple. We can run the following command to install DSPy and the required dependencies. Note that other alternatives are shown in the code comments (e.g., how to install for Pinecone). You can read more about the installation here in the DSPy docs.
1pip install dspy-ai
2# pip install "dspy-ai[pinecone]"
3# pip install "dspy-ai[chromadb]"
4# pip install "dspy-ai[mongodb]"An Example: Building a retrieval and evaluation system
We will leverage the example in the DSPy docs - the simplified Baleen example. You can read and follow along with the tutorial below or refer to the original documentation here. Note that the documentation tutorial has been modified/updated slightly to reflect DSPy changes, new models, etc.
Add models
1import dspy
2
3turbo = dspy.OpenAI(model='gpt-3.5-turbo', api_key=<REDACTED>)
4colbertv2_wiki17_abstracts = dspy.ColBERTv2(url='http://20.102.90.50:2017/wiki17_abstracts')
5
6dspy.settings.configure(lm=turbo, rm=colbertv2_wiki17_abstracts)GPT-3.5T and set up a retriever of Wikipedia data (specifically the first paragraph of articles). We then use dspy.settings to configure the language model and the retriever.
Define the model signature
1class GenerateAnswer(dspy.Signature):
2 """Answer questions with short factoid answers."""
3
4 context = dspy.InputField(desc="may contain relevant facts")
5 question = dspy.InputField()
6 answer = dspy.OutputField(desc="often between 1 and 5 words")
7
8class GenerateSearchQuery(dspy.Signature):
9 """Write a simple search query that will help answer a complex question."""
10
11 context = dspy.InputField(desc="may contain relevant facts")
12 question = dspy.InputField()
13 query = dspy.OutputField()Compose a module
1from dsp.utils import deduplicate
2
3class SimplifiedBaleen(dspy.Module):
4 def __init__(self, passages_per_hop=3, max_hops=2):
5 super().__init__()
6
7 self.generate_query = [dspy.ChainOfThought(GenerateSearchQuery) for _ in range(max_hops)]
8 self.retrieve = dspy.Retrieve(k=passages_per_hop)
9 self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
10 self.max_hops = max_hops
11
12 def forward(self, question):
13 context = []
14
15 for hop in range(self.max_hops):
16 query = self.generate_query[hop](context=context, question=question).query
17 passages = self.retrieve(query).passages
18 context = deduplicate(context + passages)
19
20 pred = self.generate_answer(context=context, question=question)
21 return dspy.Prediction(context=context, answer=pred.answer)ChainOfThought(), retrieve context, and then generate an answer. If you are curious about the forward() method, check out this part of the DSPy deep dive.
1# Ask any question you like to this simple RAG program.
2my_question = "In what year did India gain independence from British rule?"
3
4# Get the prediction. This contains `pred.context` and `pred.answer`.
5uncompiled_baleen = SimplifiedBaleen() # uncompiled (i.e., zero-shot) program
6pred = uncompiled_baleen(my_question)
7
8# Print the contexts and the answer.
9print(f"Question: {my_question}")
10print(f"Predicted Answer: {pred.answer}")
11print(f"Retrieved Contexts (truncated): {[c[:200] + '...' for c in pred.context]}")Question: In what year did India gain independence from British rule?
Predicted Answer: 1947
Retrieved Contexts (truncated): ['Speeches about Indian independence | India won independence from Britain by the Indian Independence Act 1947, ending the British Raj. This act, passed in June and receiving royal assent in July, took ...', 'Dominion of India | Between gaining independence from the United Kingdom on 15 August 1947 and the proclamation of a republic on 26 January 1950, India was an independent dominion in the British Commo...', "Independence Day (India) | Independence Day is annually celebrated on 15 August, as a national holiday in India commemorating the nation's independence from the United Kingdom on 1 August 1947, the UK...", '1947 PGA Championship | The 1947 PGA Championship was the 29th PGA Championship, held June 18–24 at Plum Hollow Country Club in Southfield, Michigan, a suburb northwest of Detroit. Jim Ferrier won the...', "1947 Masters Tournament | The 1947 Masters Tournament was the 11th Masters Tournament, held April 3–6 at Augusta National Golf Club in Augusta, Georgia. The purse was $10,000 with a winner's share of ...", 'Time Out of Mind (1947 film) | Time Out of Mind is a 1947 American drama film directed by Robert Siodmak and starring Phyllis Calvert, Robert Hutton and Ella Raines. The film was made by Universal Pic...']Optimization and Evaluation
1def validate_context_and_answer_and_hops(example, pred, trace=None):
2 if not dspy.evaluate.answer_exact_match(example, pred): return False
3 if not dspy.evaluate.answer_passage_match(example, pred): return False
4
5 hops = [example.question] + [outputs.query for *_, outputs in trace if 'query' in outputs]
6
7 if max([len(h) for h in hops]) > 100: return False
8 if any(dspy.evaluate.answer_exact_match_str(hops[idx], hops[:idx], frac=0.8) for idx in range(2, len(hops))): return False
9
10 return TrueBuild the optimizer
1from dspy.teleprompt import BootstrapFewShot
2
3optimizier = BootstrapFewShot(metric=validate_context_and_answer_and_hops)
4compiled_baleen = optimizer.compile(SimplifiedBaleen(), teacher=SimplifiedBaleen(passages_per_hop=2), trainset=trainset)BootstrapFewShot optimizer and provide our metric defiend in the previous step. The optimizer offers a compile method.
100%|██████████| 20/20 [01:33<00:00, 4.70s/it]
Bootstrapped 2 full traces after 20 examples in round 0. 1from dspy.evaluate.evaluate import Evaluate
2
3# Define metric to check if we retrieved the correct documents
4def gold_passages_retrieved(example, pred, trace=None):
5 gold_titles = set(map(dspy.evaluate.normalize_text, example["gold_titles"]))
6 found_titles = set(
7 map(dspy.evaluate.normalize_text, [c.split(" | ")[0] for c in pred.context])
8 )
9 return gold_titles.issubset(found_titles)
10
11# Set up the `evaluate_on_hotpotqa` function. We'll use this many times below.
12evaluate_on_hotpotqa = Evaluate(devset=devset, num_threads=1, display_progress=True, display_table=5)
13
14uncompiled_baleen_retrieval_score = evaluate_on_hotpotqa(uncompiled_baleen, metric=gold_passages_retrieved)
15compiled_baleen_retrieval_score = evaluate_on_hotpotqa(compiled_baleen, metric=gold_passages_retrieved)
16
17print(f"## Retrieval Score for uncompiled Baleen: {uncompiled_baleen_retrieval_score}")
18print(f"## Retrieval Score for compiled Baleen: {compiled_baleen_retrieval_score}")# Higher is better
Retrieval Score for uncompiled Baleen: 56.0
Retrieval Score for compiled Baleen: 66.0Let’s take a look at a side-by-side view of the retrieval results:
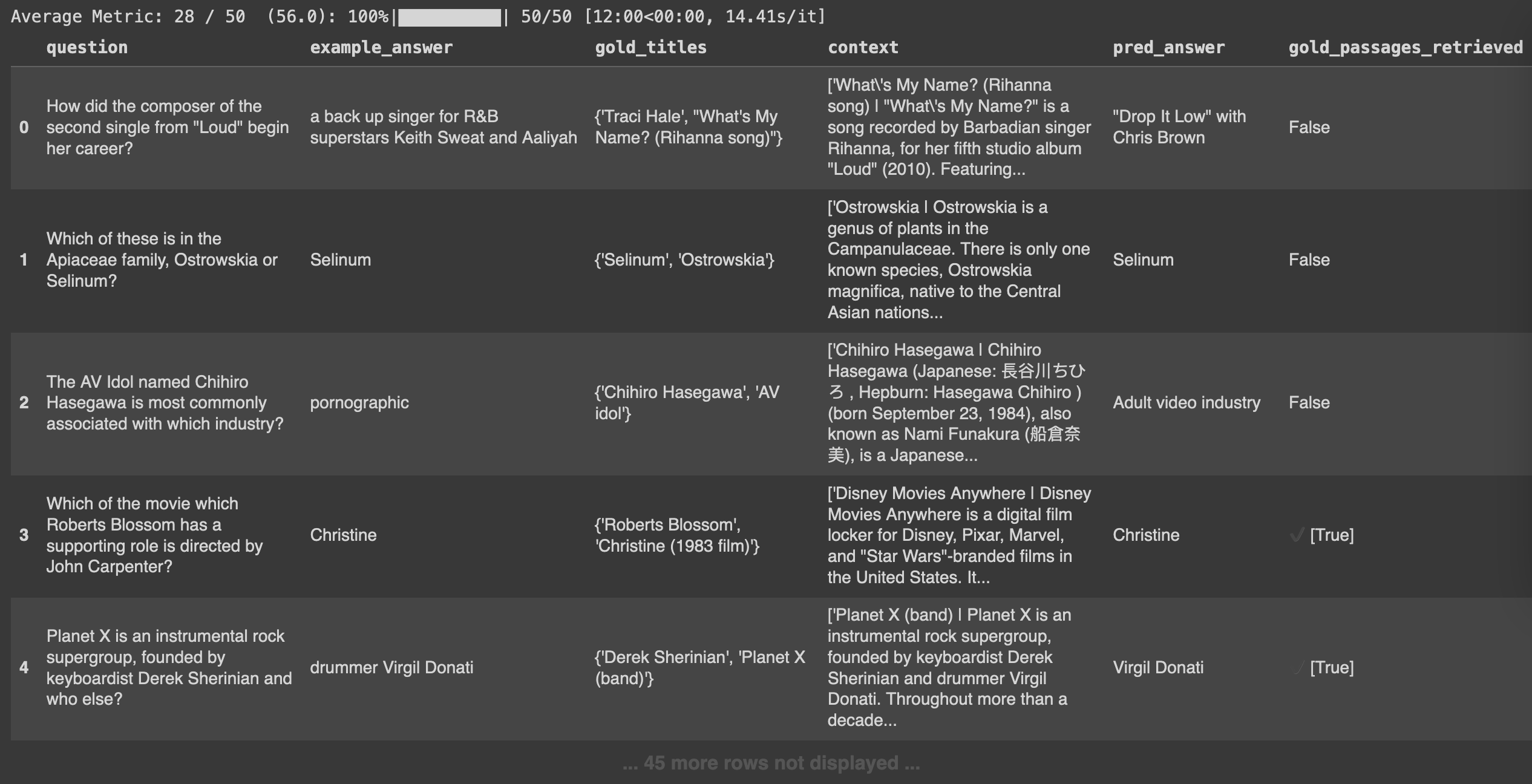
Poorer retrieval results when not compiling (Displaying 5/50 results)
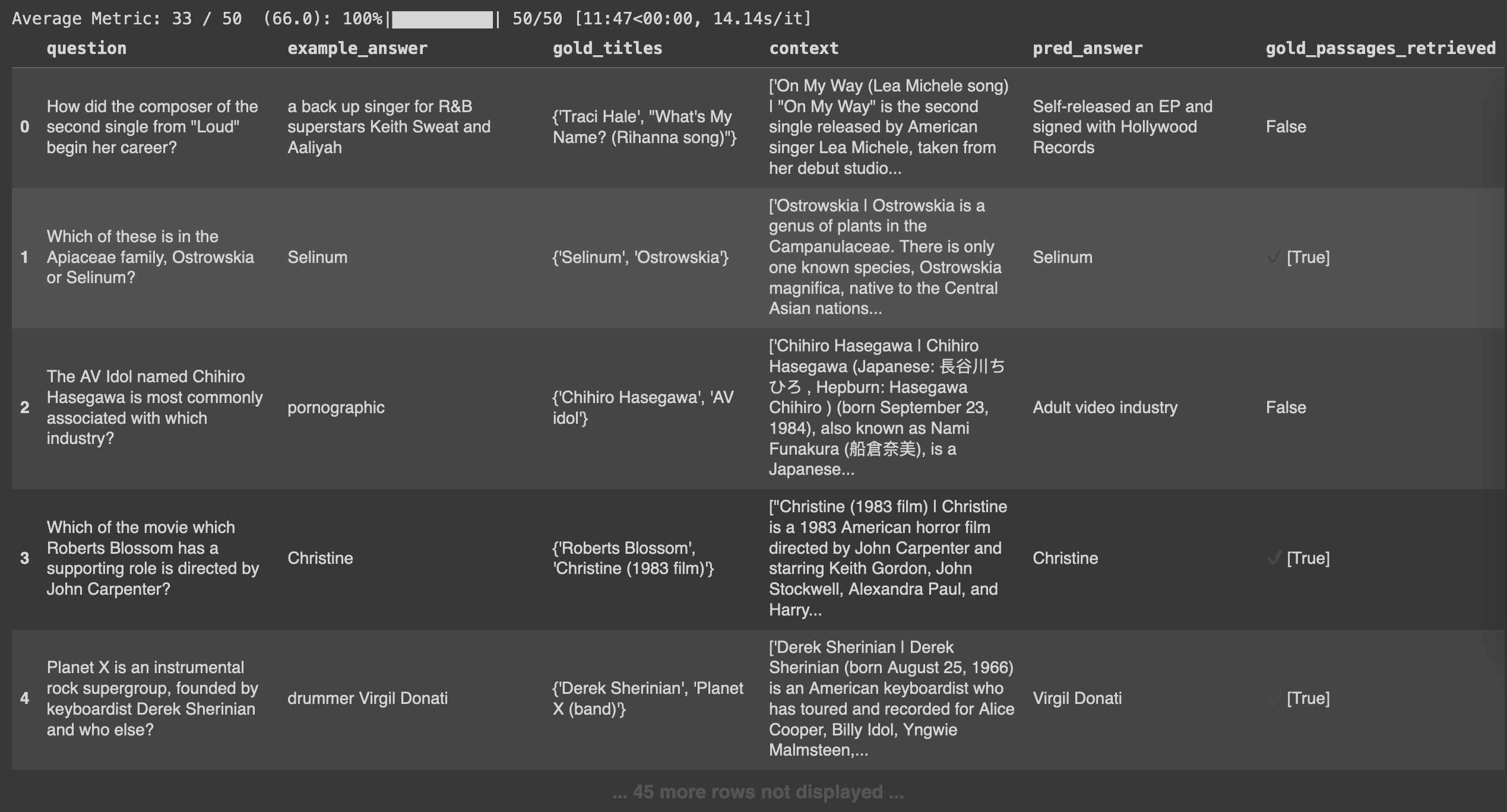
Better retrieval resutls when compiling (Displaying 5/50 results)
Please feel free to reach out if you would like access to the notebook (.ipynb) on Google Colab.
Let's take a moment to reflect on what we have accomplished above. We've successfully:
- recognized that working with splintery AI models and tools necessitates usage of compound AI systems
- built our intuition for why programmatic and algorithmic optimization is needed, especially for large-scale, enterprise AI systems
- reviewed
DSPyand the DSPy components - built a multi-model retrieval system with tooling that helps optimize and evaluate performance
- demonstrated how compiling multi-step AI programs can improve quality and performance
The benefits of this approach are that we can reduce time spent with fragile prompt-tinkering, reduce cost by leveraging smaller, pre-trained models, and more easily maintain this solution as models come and go. Given the nature of generative AI, this space is evolving rapidly so expect change. If you are interested in this subject, please feel free to reach out or refer to the resources below.
Additional Resources
- DSPy Docs: About DSPy
- Github: StanfordNLP/DSPy
- Berkeley Artific ial Intelligence Research (BAIR): The Shift from Models to Compound AI Systems (Zaharia et al., 2024)
- Databricks Mosaic AI Research: DSPy on Databricks
- Databricks Mosaic AI Research: Optimizing Databricks LLM Pipelines with DSPy
- YouTube (Data+AI Summit) - Prompt Engineering is Dead; Build LLM Applications with DSPy Framework
- YouTube (Data+AI Summit) - Applications of Stanford DSPy for Self-Improving Language Model Pipelines
- DSPy Docs: Deep Dive
- DSPy Docs: DSPy Cheatsheet
- DSPy Docs: Leverage Databricks Model Serving
