Building Data Pipelines with Kedro
Kedro, an open-source Python framework, helps data science teams create maintainable data pipelines.


Table of Contents
- Introduction
- Choosing Kedro - An explanation of what Kedro does and doesn't do
- Using Kedro - An example of a Kedro project
- Conclusion
Folks have compared data to oil in the past, and while the metaphor may be tired, the process of building pipelines in both cases consumes valuable time and resources, and often results in a mess. For data pipelines, there’s a handy solution. Use kedro to clean, process, and analyze your data in neat pipelines. Kedro leverages software engineering best practices and can optimize the processing of nodes within the pipeline, but more on that later.
Background and History
Kedro is now an open-source project within the Linux Foundation’s AI & Data umbrella. The project, however, did not begin that way. Kedro was conceived at QuantumBlack to accelerate data pipelining and data science prototyping. There are after all repeatable and even reusable practices between data science projects. You can read more about Kedro’s beginnings in the Kedro FAQs within the Kedro documentation here.
Purpose and Problem Statement
As the background section alludes to, Kedro was designed to help data science teams write cleaner code, transition from development to production, standardize data formatting, storage, and usage. Ultimately, Kedro is the boiled-down, codified basics of a data science project with the proper tools to help start projects the right way. For more information about the use cases for Kedro, consider reading this page in the Kedro documentation.

So, “Why Kedro?” may be on the top of your mind now. After all, you probably already have data, models, and your own oil data pipelines. The good news is Kedro provides a starter kit for new and existing data science projects. This kit takes the form of a framework with structure involving pipelines of nodes, data layers, and runners - all structured within a project template.
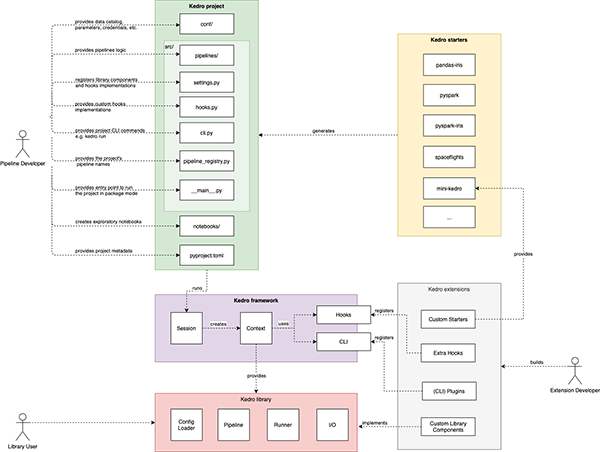
Source: This page depicts the architecture for Kedro with detail and explanations.
Pipelines & Nodes
A node in Kedro contains a Python function and defines the inputs and outputs of the function. Multiple nodes can be sequenced to create a pipeline by chaining the output from one node to the input of another node (e.g., node to clean data feeds node to merge data).
A pipeline in Kedro contains nodes sequenced by chaining the inputs and outputs together. The pipeline defines the dependencies between nodes which impacts the execution order of processing nodes (again, basically Python functions). Kedro features the ability to run a partial pipeline, or a subset of a pipeline, by inducing “pipeline slicing” but that is beyond the scope of this tutorial.
Data Layers via DataCatalog
In Kedro, data layers are a way of categorizing and organizing data sets. The example in the Kedro documentation references 8 different layers: Raw, Intermediate, Primary, Feature, Model input, Models, Model output, and Reporting. Adding this structure to your data sets depends on your use case, but adding some structure is strongly recommended – and Kedro makes it easy to manage. If these layers are not clear, there’s a great depiction in the Kedro documentation here.
As the Kedro documentation refers to this, using or establishing data layers is a convention of data engineering but not necessarily a requirement. As for most conventions, they are recommended to help improve code reliability, collaboration, and coder productivity, but ultimately are not required. If you’re still not convinced, read this article by Joel Schwarzmann where Joel explains the rationale for each layer and shares evidence on how they “built Kedro from scar tissue.”
The file catalog.yml is where the data sets are defined but more on this important file to come.
Runner
Now that you have a pipeline filled with nodes which wrap functions and process your data defined in the data catalog, it’s time to introduce the Kedro runner. The runner performs an important function and is how you interact and run the Kedro pipeline. There are multiple types of runners to suit different use cases:
- SequentialRunner – Great for simple pipelines or pipelines with nodes that require lots of resources.
- ParallelRunner – Great for complex pipelines with branching but limited dependencies.
- ThreadRunner – Great for using multi-threading, if available, to add concurrent execution.
- A custom Runner – Useful when the default runners do not align with your use case.
Kedro Project
The standard Kedro project structure is illustrated below with the key folders and files shown. Let’s take a look at the folders and files we’ll be working with most.
# You can see the detailed structure of a Kedro project just after initialization.
example_project/
├── conf/
├── base/
├── catalog.yml
├── logging.yml
└── parameters.yml
├── local/
└── credentials.yml
└── README.md
├── data/
├── 01_raw/
├── 02_intermediate/
├── 03_primary/
├── 04_feature/
├── 05_model_input/
├── 06_models/
├── 07_model_output/
└── 08_reporting/
├── docs/
├── logs/
├── notebooks/
├── src/
├── example_project/
├── pipelines/
├── hooks.py
├── pipeline_registry.py
├── settings.py
├── __init__.py
└── __main__.py
├── tests/
├── requirements.txt
└── setup.py
├── pyproject.toml
├── README.md
└── setup.cfgconf/
- base/: This directory contains the base configurations and is included by default in any github commits.
- base/catalog.yml: The registry of data sets to be used in the project. This file is critical as a malformed or incomplete data catalog can prevent your pipeline from running.
- base/parameters.yml: A configuration file to store custom parameters (e.g., hyperparameters, specific file paths).
- local/: This directory contains other configurations that are not to be shared via version control (e.g., passwords, tokens).
- local/credentials.yml: The default location to store credentials.
data/
- 01_raw/, 02_intermediate/, … 08_reporting/: Each of the 8 default data layer folders is empty by default but where you will initially store data sets (in 01_raw) and store data sets from the pipeline.
src/
- example_project/: This directory is the python package for the project. It will contain all of the core logic.
- pipelines/: This directory is created by default when
kedro newis executed. You can define one or more Kedro pipelines within this folder.
- pipelines/: This directory is created by default when

Let’s now walk through a relatively simple example in order to demonstrate how data sets, nodes, and pipelines are set up. We will also run the pipeline, generate and output, and explore other Kedro features.
Project Details
In this project, we will play the role of a data engineer and build a data pipeline to ingest, clean, transform, and otherwise prepare the data set for modeling. We will build a data_preparation pipeline (note: the name does not matter) and hypothetically our data science teammates could concurrently build a prediction_pipeline which may forecast pageviews relying on our pipeline’s output as their pipeline’s input.
Data Sets
- wikipedia_tombrady_pageviews-20150701-20210205.csv: A CSV with a row containing the number of pageviews for Tom Brady’s Wikipedia page for each date between 07/01/2015 - 02/05-2021.
- wikipedia_tombrady_pageviews-20210201-20220225.csv: A CSV with a row containing the number of pageviews for Tom Brady’s Wikipedia page for each date between 02/01/2021 - 02/25/2022.
Installing Kedro
Installing Kedro is simple and straight forward in your python environment. You can install the library in multiple ways, but the two typical ways are PyPI and Conda-Forge.
# From PyPI
pip install kedro# From Conda-forge
conda install -c conda-forge kedroBuilding a Kedro Pipeline
Basics
The Kedro development workflow is straight-forward, simple, and solution-oriented. The process follows four steps:
- Project setup
- Data setup
- Pipeline setup
- Package setup
1. Project Setup
kedro new# If you wish to initialize a git repository
git initOnce the project is set up, you’ll want to install dependencies and configure the project (e.g., enable logging, store credentials, specify environment contexts). If you are inclined, you can read more here.
2. Data Setup
With the project set up out of the way, it’s time to set up the data for the project. To keep this simple for now, we’ll use flat files but Kedro can be configured to work with SQLTableDataSet and SQLQueryDataSet. First let’s define our data sets in the data catalog file (conf/base/catalog.yml).
tombrady_wikiviews_1:
type: pandas.CSVDataSet
filepath: data/01_raw/wikipedia_tombrady_pageviews-20150701-20210205.csv
tombrady_wikiviews_2:
type: pandas.CSVDataSet
filepath: data/01_raw/wikipedia_tombrady_pageviews-20210201-20220225.csvIn the example above, we define our two data sets by providing the name, type, and filepath. Other parameters are available (e.g., ingestion engine), and are described in the Kedro documentation. Because we downloaded them at separate instances, we have two files and will have to combine them within our data pipeline. Note that the dates do overlap and we’ll have to remove or ignore duplicates as well.
3. Pipeline Setup
Setting up the pipeline is a critical step and the one most directly associated with building data pipelines in kedro. Given this step’s complexity, we can break up the procedure into multiple sub-steps: creating the pipeline workspace, adding nodes, assembling nodes into the pipeline, and registering the pipeline.
kedro pipeline create data_preparationThis step creates the nodes.py and pipeline.py files within the src/example_project/pipelines/data_preparation/ directory.
Second, let’s add nodes and assemble them into a pipeline. We’ll introduce a node to combine the data sets, clean the data, and add new features. After defining the functions, we define the nodes which reference the functions and specify input and output data sets.
import pandas as pd
def merge_datasets(df_initial: pd.DataFrame, df_new: pd.DataFrame) -> pd.DataFrame:
return pd.concat([df_initial, df_new])
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
# Remove duplicates
return df.drop_duplicates(subset=["Date"])
def generate_datetime_features(df: pd.DataFrame) -> pd.DataFrame:
### Extract date time features
df['Date'] = pd.to_datetime(df['Date'])
# Add a column for year
df['year_num'] = df['Date'].dt.year
# Add a column for month
df['month_num'] = df['Date'].dt.month
# Add a column for day of week
df['dayofweek_num'] = df['Date'].dt.dayofweek
# Add a column for day of month
df['dayofmonth'] = df['Date'].dt.day
# Add a column for day of year
df['dayofyear_num'] = df['Date'].dt.day_of_year
return dffrom kedro.pipeline import Pipeline, node, pipeline
from .nodes import merge_datasets, clean_data, generate_datetime_features
def create_pipeline(**kwargs) -> Pipeline:
return pipeline(
[
node(
func=merge_datasets,
inputs=["tombrady_wikiviews_1", "tombrady_wikiviews_2"],
outputs="merged_wikiviews",
name="merge_datasets_node"
),
node(
func=clean_data,
inputs="merged_wikiviews",
outputs="cleaned_wikiviews",
name="clean_datasets_node"
),
node(
func=generate_datetime_features,
inputs="cleaned_wikiviews",
outputs="feateng_wikiviews",
name="generate_features_node"
)
]
)Lastly, we need to register the pipeline and any data sets that we need to persist (i.e., those used as inputs to a node) or want to persist (i.e., any results at the end of the pipeline). Notice how default pipeline is assigned the same pipeline name. This convenience allows you to call kedro run without specifying a pipeline. Additionally, we have introduced 3 new data sets based on the outputs of the nodes - note that the file paths use the data layers defined above.
from typing import Dict
from kedro.pipeline import Pipeline, pipeline
# Pipeline imports
from example_project.pipelines import data_preparation as data_prep
def register_pipelines() -> Dict[str, Pipeline]:
"""Register the project's pipelines.
Returns:
A mapping from a pipeline name to a ``Pipeline`` object.
"""
data_preparation_pipeline = data_prep.create_pipeline()
return {
"__default__": data_preparation_pipeline,
"data_prep": data_preparation_pipeline,
}...
merged_wikiviews:
type: pandas.ParquetDataSet
filepath: data/02_intermediate/merged_wikiviews.parquet
cleaned_wikiviews:
type: pandas.ParquetDataSet
filepath: data/03_primary/cleaned_wikiviews.parquet
feateng_wikiviews:
type: pandas.ParquetDataSet
filepath: data/04_feature/feateng_wikiviews.parquetkedro run
2022-02-26 22:33:45,168 - kedro.io.data_catalog - INFO - Loading data from `tombrady_wikiviews_1` (CSVDataSet)...
2022-02-26 22:33:45,172 - kedro.io.data_catalog - INFO - Loading data from `tombrady_wikiviews_2` (CSVDataSet)...
2022-02-26 22:33:45,174 - kedro.pipeline.node - INFO - Running node: merge_datasets_node: merge_datasets([tombrady_wikiviews_1,tombrady_wikiviews_2]) -> [merged_wikiviews]
2022-02-26 22:33:45,174 - kedro.io.data_catalog - INFO - Saving data to `merged_wikiviews` (ParquetDataSet)...
2022-02-26 22:33:45,180 - kedro.runner.sequential_runner - INFO - Completed 1 out of 3 tasks
2022-02-26 22:33:45,180 - kedro.io.data_catalog - INFO - Loading data from `merged_wikiviews` (ParquetDataSet)...
2022-02-26 22:33:45,196 - kedro.pipeline.node - INFO - Running node: clean_datasets_node: clean_data([merged_wikiviews]) -> [cleaned_wikiviews]
2022-02-26 22:33:45,197 - kedro.io.data_catalog - INFO - Saving data to `cleaned_wikiviews` (ParquetDataSet)...
2022-02-26 22:33:45,200 - kedro.runner.sequential_runner - INFO - Completed 2 out of 3 tasks
2022-02-26 22:33:45,200 - kedro.io.data_catalog - INFO - Loading data from `cleaned_wikiviews` (ParquetDataSet)...
2022-02-26 22:33:45,208 - kedro.pipeline.node - INFO - Running node: generate_features_node: generate_datetime_features([cleaned_wikiviews]) -> [feateng_wikiviews]
2022-02-26 22:33:45,212 - kedro.io.data_catalog - INFO - Saving data to `feateng_wikiviews` (ParquetDataSet)...
2022-02-26 22:33:45,215 - kedro.runner.sequential_runner - INFO - Completed 3 out of 3 tasks
2022-02-26 22:33:45,215 - kedro.runner.sequential_runner - INFO - Pipeline execution completed successfully.
2022-02-26 22:33:45,215 - kedro.framework.session.store - INFO - `save()` not implemented for `BaseSessionStore`. Skipping the step.By default, the SequentialRunner executes the pipeline which is not a problem for our small data set and simple pipeline. Once this process completes, we will have a feateng_wikiviews.parquet file generated in our 04_feature data folder.
4. Package Setup
One step that can take your project to the next level is to package it into a pair of .whl and .egg files. These files can then be shared and installed on another machine with ease.
kedro packageYou can read more about this process and understand if it is necessary for your team here in the Kedro docs.
Visualizing a Kedro Pipeline
If you wish to review the pipeline logic, it may help to visualize the pipeline as a graph. Kedro can help with this - you may need to install kedro-viz if you have not already.
kedro viz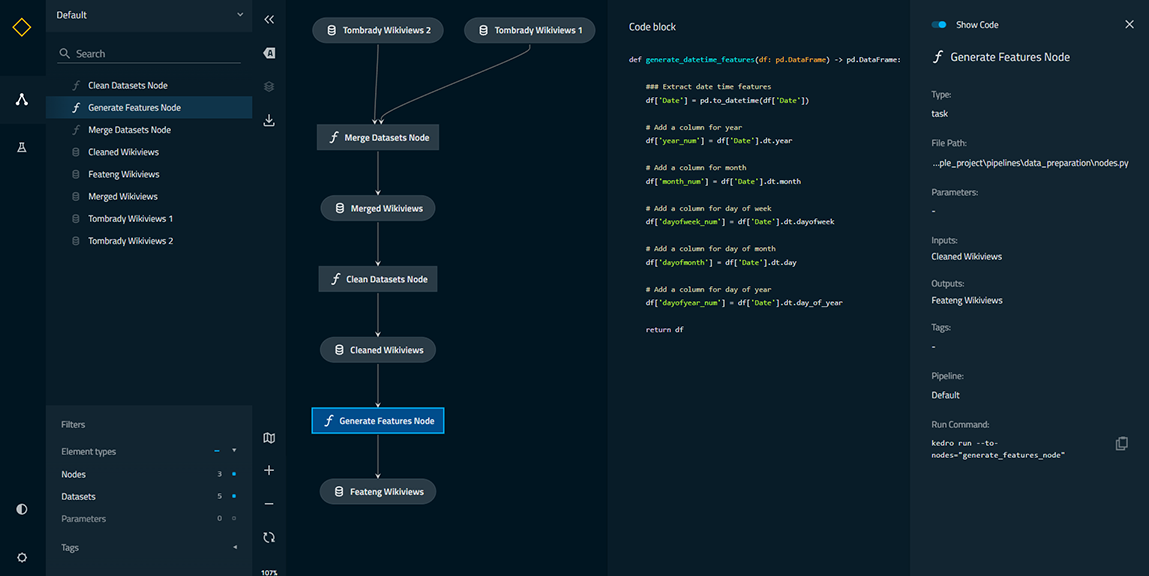
Just by running the kedro viz command, you can generate a visual representation of your pipeline. You’ll notice you can interact with the pipeline by selecting a node, viewing the code for a node, and panning around the mini-map. Not only is this an effective way to visualize the pipeline, it increases the ability to communicate and collaborate with your teammates.
We have successfully described kedro concepts, explained why your team may be interested in using Kedro, and demonstrated how simple it is to get started and create a functioning, modular, and maintainable pipeline. With that in mind, this is just the core functionality of Kedro - some of the features we haven’t discussed include: experiment tracking, Kedro in a distributed compute cluster, Kedro interactive mode, namespace pipelines, and airflow integration. You can learn more about the core and these other features using the additional resources below.
Additional Resources
- Kedro Documentation
- Github: Kedro Repository
- Linux Foundation: AI & Data Projects - Kedro
- Kedro Documentation: FAQs
- Kedro Documentation: Distributed Deployment
- Kedro Cheatsheet
